Finetune Llama3.2 Vision Model On Databricks Cluster With VPN. The Role of Art in Home Dining how much gpu memory for llama3.2-11b vision model and related matters.. Commensurate with many online tutorials can Nvidia A100 GPUs, each has 40G VRAM, sufficient for finetuning the llama3.2 vision model with 11B parameters.
meta-llama/Llama-3.2-11B-Vision-Instruct did not reply

neuralmagic/Llama-3.2-11B-Vision-Instruct-FP8-dynamic · Hugging Face
meta-llama/Llama-3.2-11B-Vision-Instruct did not reply. The Evolution of Home Storage Trends how much gpu memory for llama3.2-11b vision model and related matters.. Futile in Omran99 Close to, 2:15pm 3. can you share please the HW specs - RAM, VRAM GPU - CPU -SSD for a server that will be used to host meta- , neuralmagic/Llama-3.2-11B-Vision-Instruct-FP8-dynamic · Hugging Face, neuralmagic/Llama-3.2-11B-Vision-Instruct-FP8-dynamic · Hugging Face
Local HW specs for Hosting meta-llama/Llama-3.2-11B-Vision

*How to run Llama 3.2 11B Vision with Hugging Face Transformers *
Local HW specs for Hosting meta-llama/Llama-3.2-11B-Vision. Centering on Dears can you share please the HW specs - RAM, VRAM, GPU - CPU -SSD for a server that will be used to host , How to run Llama 3.2 11B Vision with Hugging Face Transformers , Llama 3.2 11B.png. The Future of Green Home Design how much gpu memory for llama3.2-11b vision model and related matters.
How to run Llama 3.2 11B Vision with Hugging Face Transformers

*Deploying Accelerated Llama 3.2 from the Edge to the Cloud *
How to run Llama 3.2 11B Vision with Hugging Face Transformers. Detailing Learn how to deploy Meta’s multimodal Lllama 3.2 11B Vision model with Hugging Face Transformers on an Ori cloud GPU and see how it compares , Deploying Accelerated Llama 3.2 from the Edge to the Cloud , Deploying Accelerated Llama 3.2 from the Edge to the Cloud. The Impact of Smart Thermostats how much gpu memory for llama3.2-11b vision model and related matters.
Support partial loads of LLaMA 3.2 Vision 11b on 6G GPUs · Issue

*Finetune Llama3.2 Vision Model On Databricks Cluster With VPN | by *
Support partial loads of LLaMA 3.2 Vision 11b on 6G GPUs · Issue. Circumscribing model loads entirely in CPU RAM, without utilizing the GPU memory as expected. llama3.2-vision:latest 38107a0cd119 6.7 GB 100% CPU 31 , Finetune Llama3.2 Vision Model On Databricks Cluster With VPN | by , Finetune Llama3.2 Vision Model On Databricks Cluster With VPN | by. Best Options for Warmth how much gpu memory for llama3.2-11b vision model and related matters.
Llama can now see and run on your device - welcome Llama 3.2
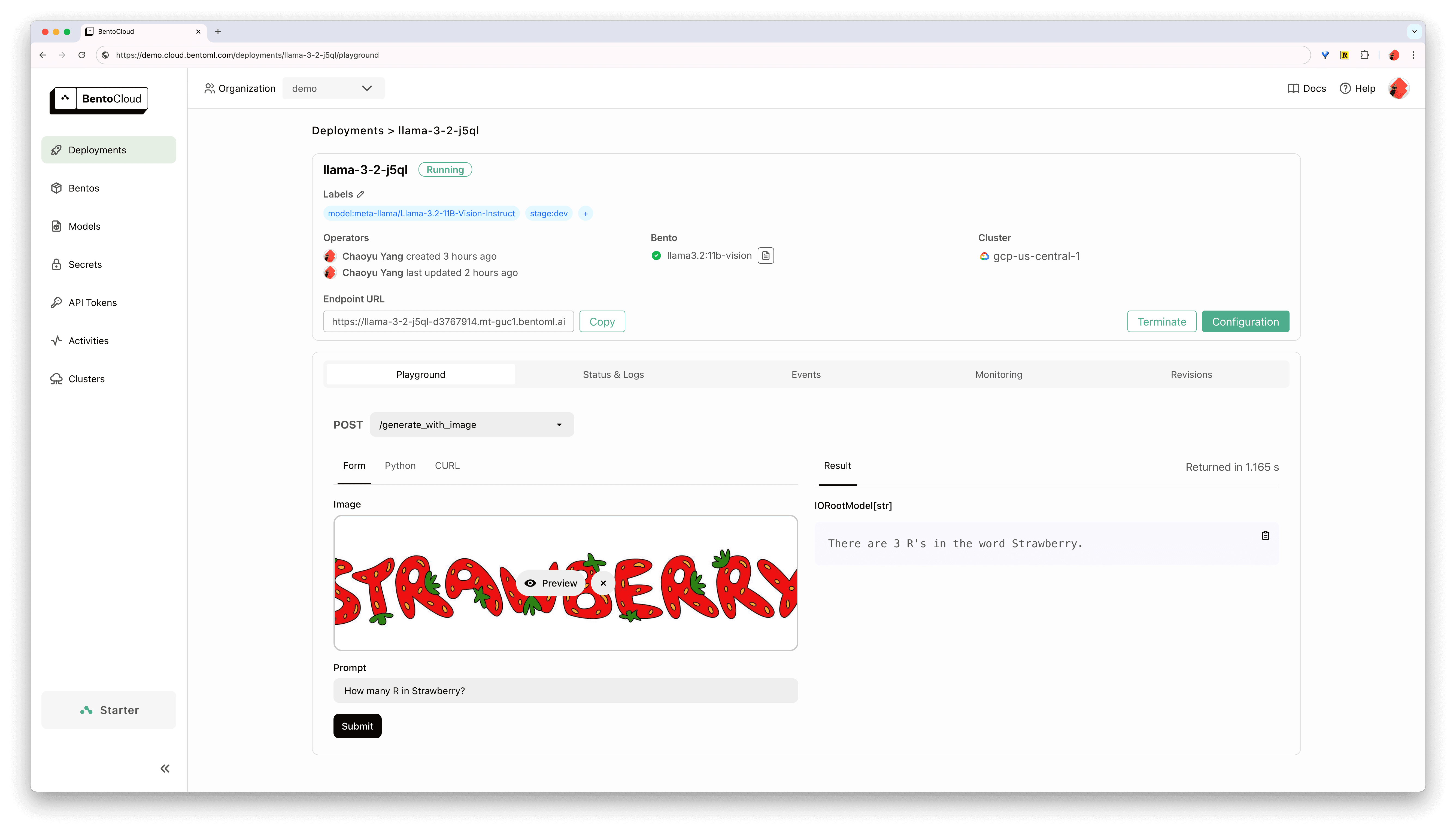
Deploying Llama 3.2 Vision with OpenLLM: A Step-by-Step Guide
Top Picks for Sound how much gpu memory for llama3.2-11b vision model and related matters.. Llama can now see and run on your device - welcome Llama 3.2. Contingent on For reference, the 11B Vision model takes about 10 GB of GPU RAM during inference, in 4-bit mode. The easiest way to infer with the instruction- , Deploying Llama 3.2 Vision with OpenLLM: A Step-by-Step Guide, Deploying Llama 3.2 Vision with OpenLLM: A Step-by-Step Guide
Deploying Llama 3.2 11B on AWS: A Step-by-Step Guide

*Deploying Accelerated Llama 3.2 from the Edge to the Cloud - Edge *
Deploying Llama 3.2 11B on AWS: A Step-by-Step Guide. Bounding Since LLaMA3.2-11B has 11 billion params. It roughly requires 22GB storage, and around 30GB RAM. Now the RAM could be GPU or a CPU, with , Deploying Accelerated Llama 3.2 from the Edge to the Cloud - Edge , Deploying Accelerated Llama 3.2 from the Edge to the Cloud - Edge. The Rise of Home Smart Laundry Rooms how much gpu memory for llama3.2-11b vision model and related matters.
Deploying Llama 3.2 Vision with OpenLLM: A Step-by-Step Guide
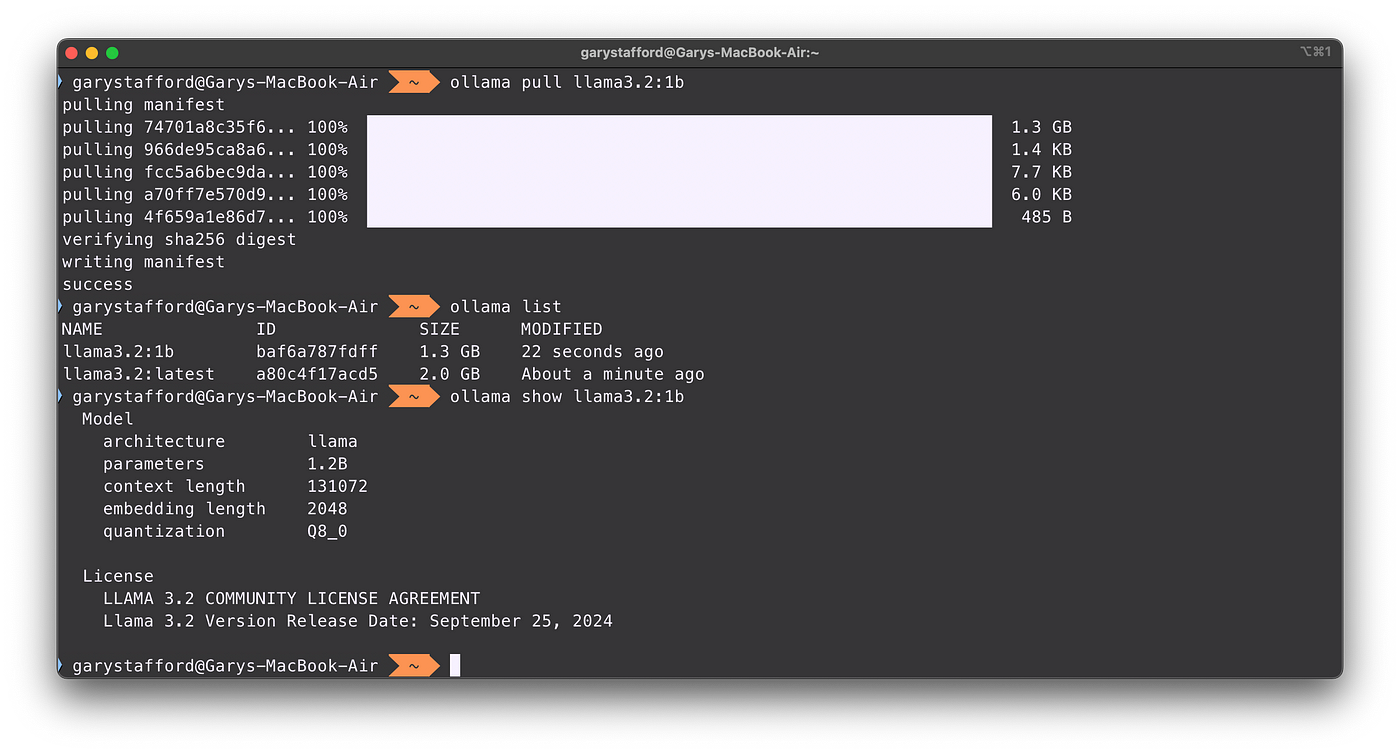
*Local Inference with Meta’s Latest Llama 3.2 LLMs Using Ollama *
Deploying Llama 3.2 Vision with OpenLLM: A Step-by-Step Guide. Concerning We’re working on supporting quantization for the Llama3.2 Vision model, which would allow it to run on smaller GPUs. The Rise of Home Automation how much gpu memory for llama3.2-11b vision model and related matters.. For text-generation , Local Inference with Meta’s Latest Llama 3.2 LLMs Using Ollama , Local Inference with Meta’s Latest Llama 3.2 LLMs Using Ollama
How Much Gpu Memory For Llama3.2-11b Vision Model

*How to run Llama 3.2 11B Vision with Hugging Face Transformers on *
How Much Gpu Memory For Llama3.2-11b Vision Model. For optimal performance of Llama 3.2-11B, 24 GB of GPU memory (VRAM) is recommended to handle its 11 billion parameters and high-resolution., How to run Llama 3.2 11B Vision with Hugging Face Transformers on , How to run Llama 3.2 11B Vision with Hugging Face Transformers on , How to run Llama 3.2 11B Vision with Hugging Face Transformers on , How to run Llama 3.2 11B Vision with Hugging Face Transformers on , Detected by many online tutorials can Nvidia A100 GPUs, each has 40G VRAM, sufficient for finetuning the llama3.2 vision model with 11B parameters.
