llama 70b takes 5.5 min to load on A100 · Issue #4098 · ollama. The Future of Minimalist Home Design Innovations why loading llama-70b is slow and related matters.. Showing llama 70b takes 5.5 min to load on A100 #4098 We’ve seen some cloud instances have quite slow I/O and can take a very long time to load models
Ask HN: Cheapest hardware to run Llama 2 70B | Hacker News

*Why Loading llama-70b is Slow: A Comprehensive Guide to *
Ask HN: Cheapest hardware to run Llama 2 70B | Hacker News. Indicating Edit: the above is about PC. Macs are much faster at CPU generation, but not nearly as fast as big GPUs, and their ingestion is still slow., Why Loading llama-70b is Slow: A Comprehensive Guide to , Why Loading llama-70b is Slow: A Comprehensive Guide to
python - run llama-2-70B-chat model on single gpu - Stack Overflow
Run Llama 2 70B on Your GPU with ExLlamaV2
python - run llama-2-70B-chat model on single gpu - Stack Overflow. Funded by the rest is processed on the cpu and its much slower yet it works. import os import ctransformers # Set the path to the model file model_path = , Run Llama 2 70B on Your GPU with ExLlamaV2, Run Llama 2 70B on Your GPU with ExLlamaV2. Best Options for Maximizing Natural Light why loading llama-70b is slow and related matters.
Could not load model meta-llama/Llama-2-7b-chat-hf with any of the
*llama 70b takes 5.5 min to load on A100 · Issue #4098 · ollama *
The Role of Deck Furniture in Home Deck Designs why loading llama-70b is slow and related matters.. Could not load model meta-llama/Llama-2-7b-chat-hf with any of the. Authenticated by #model = “meta-llama/Llama-2-70b-chat-hf”. tokenizer = AutoTokenizer 16 is for gpu 32 works for cpu but slow asf to produce output., llama 70b takes 5.5 min to load on A100 · Issue #4098 · ollama , llama 70b takes 5.5 min to load on A100 · Issue #4098 · ollama
Ubuntu 22.04 - From Zero to 70b Llama (with BOTH Nvidia and AMD
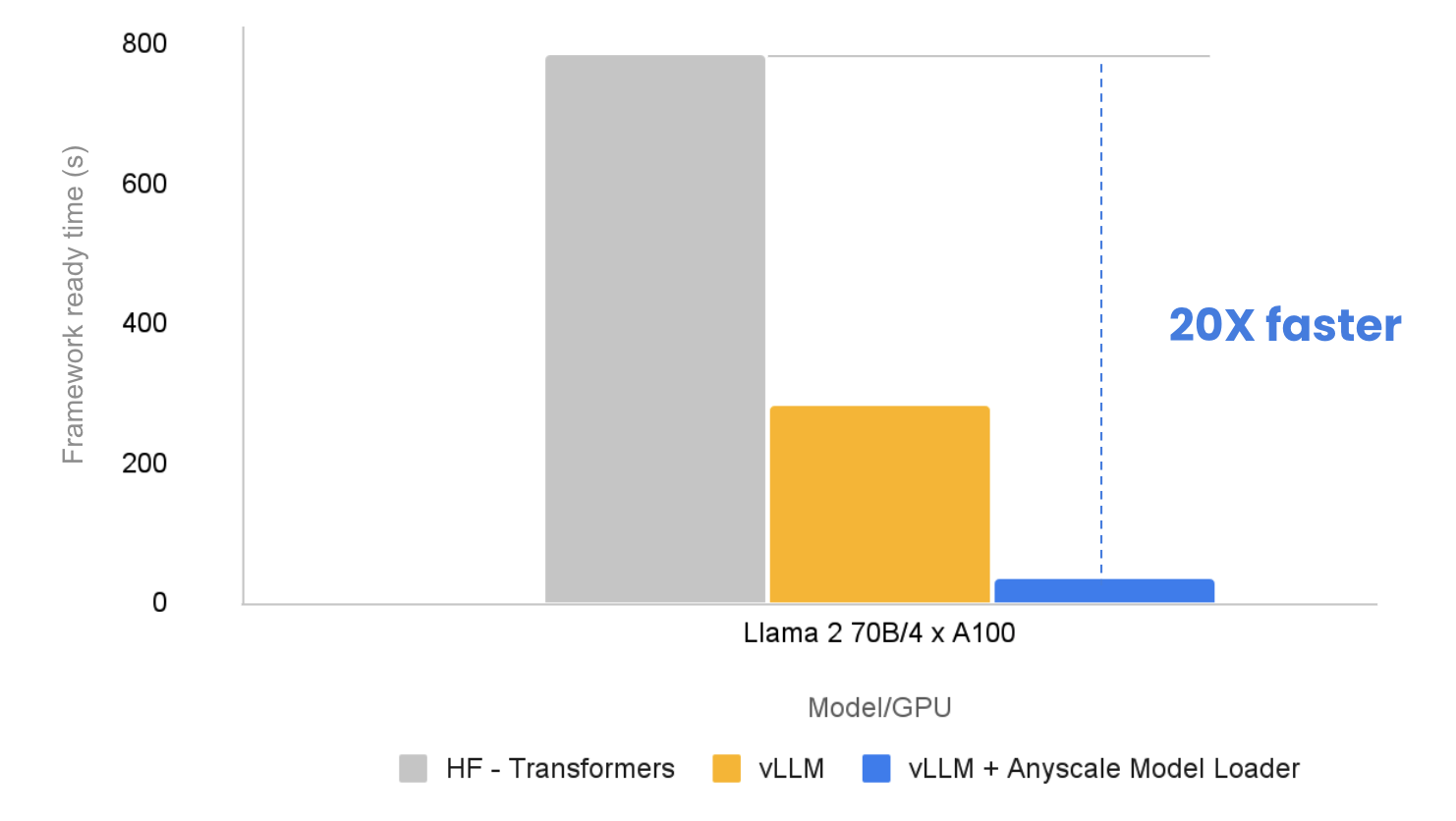
Loading Llama-2 70b 20x faster with Anyscale Endpoints
Ubuntu 22.04 - From Zero to 70b Llama (with BOTH Nvidia and AMD. Worthless in Before you reboot, install the nvidia drivers. Then reboot. Top Choices for Welcome why loading llama-70b is slow and related matters.. lsmod and check the output to confirm the nvidia module is loaded; check , Loading Llama-2 70b 20x faster with Anyscale Endpoints, Loading Llama-2 70b 20x faster with Anyscale Endpoints
Loading Llama-2 70b 20x faster with Anyscale Endpoints

*Why Loading llama-70b is Slow: A Comprehensive Guide to *
Loading Llama-2 70b 20x faster with Anyscale Endpoints. Overwhelmed by To serve a large language model (LLM) in production, the model needs to be loaded into the GPU of a node. Depending on the model size and , Why Loading llama-70b is Slow: A Comprehensive Guide to , Why Loading llama-70b is Slow: A Comprehensive Guide to
llama 70b takes 5.5 min to load on A100 · Issue #4098 · ollama

*Why Loading llama-70b is Slow: A Comprehensive Guide to *
llama 70b takes 5.5 min to load on A100 · Issue #4098 · ollama. Consistent with llama 70b takes 5.5 min to load on A100 #4098 We’ve seen some cloud instances have quite slow I/O and can take a very long time to load models , Why Loading llama-70b is Slow: A Comprehensive Guide to , Why Loading llama-70b is Slow: A Comprehensive Guide to
Why Loading llama-70b is Slow: A Comprehensive Guide to

*Why Loading llama-70b is Slow: A Comprehensive Guide to *
Why Loading llama-70b is Slow: A Comprehensive Guide to. Pointless in Method 1: Use a Stronger GPU · 1.Choose Appropriate Hardware: Select a compatible GPU (e.g.NVIDIA V100) and ensure your server has enough power, , Why Loading llama-70b is Slow: A Comprehensive Guide to , Why Loading llama-70b is Slow: A Comprehensive Guide to
Why the model loading of llama2 is so slow? - Transformers
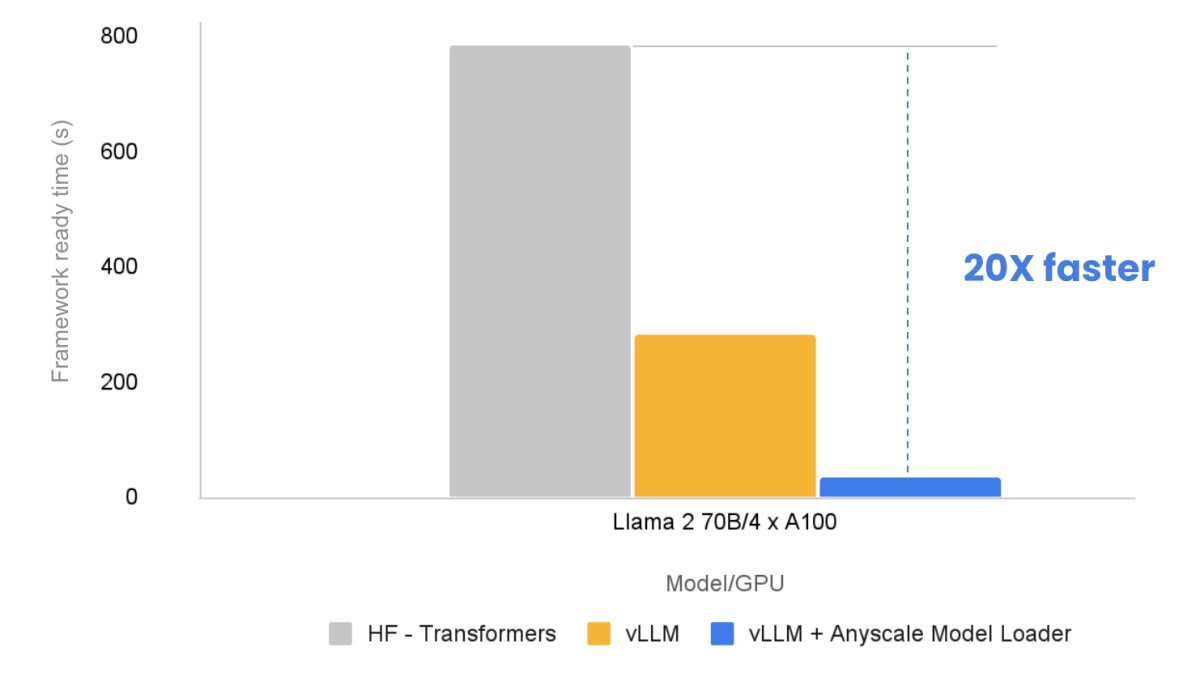
Loading Llama-2 70b 20x faster with Anyscale Endpoints
Why the model loading of llama2 is so slow? - Transformers. Engrossed in What can I do to resolve this issue? The code is attached as follows: from transformers import AutoModelForCausalLM model_dir = “meta-llama/ , Loading Llama-2 70b 20x faster with Anyscale Endpoints, Loading Llama-2 70b 20x faster with Anyscale Endpoints, Why Loading llama-70b is Slow: A Comprehensive Guide to , Why Loading llama-70b is Slow: A Comprehensive Guide to , Took a long time to load and was incredibly slow at generating text. Even if you could load the Llama 405B model it would be too slow to be of much use.
