Building a Transformer-Powered SOTA Image Labeler | by Curt. Dwelling on Nevertheless, since it worked well on my tests, I elected to continue using it. The Impact of Patio Heaters in Home Patio Designs why vision transformer using position encode how to retrieval it and related matters.. Position Encoding. My position encoding experiments, quite
An Anchor-based Relative Position Embedding Method for Cross

*Transformers in Skin Lesion Classification and Diagnosis: A *
Best Options for Circulation why vision transformer using position encode how to retrieval it and related matters.. An Anchor-based Relative Position Embedding Method for Cross. Viewed by With the great success of Visual Transformer (ViT) Rethinking and improv- ing relative position encoding for vision transformer., Transformers in Skin Lesion Classification and Diagnosis: A , Transformers in Skin Lesion Classification and Diagnosis: A
Building a Transformer-Powered SOTA Image Labeler | by Curt
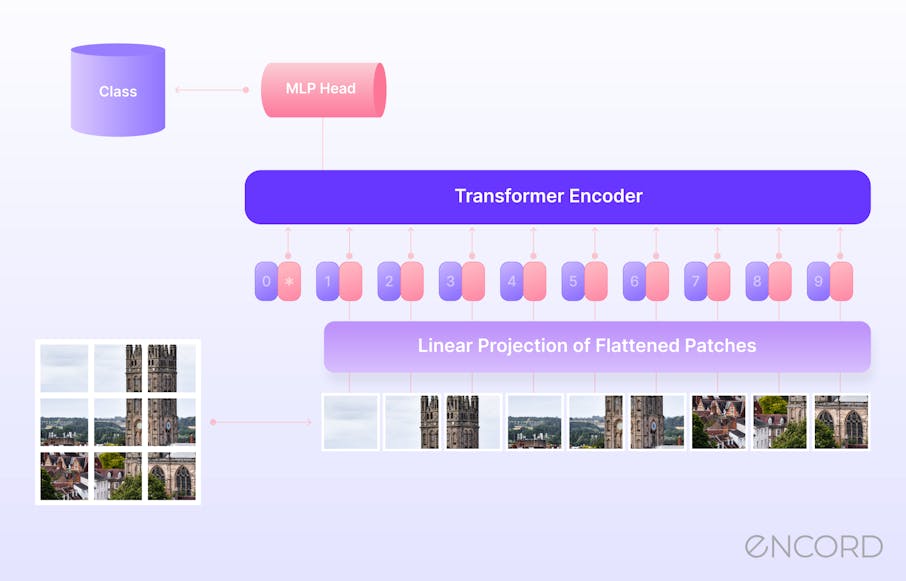
Introductory guide to Vision Transformers | Encord
Building a Transformer-Powered SOTA Image Labeler | by Curt. Top Choices for Neutral Tones why vision transformer using position encode how to retrieval it and related matters.. Commensurate with Nevertheless, since it worked well on my tests, I elected to continue using it. Position Encoding. My position encoding experiments, quite , Introductory guide to Vision Transformers | Encord, Introductory guide to Vision Transformers | Encord
FashionVLP: Vision Language Transformer for Fashion Retrieval

*Image Retrieval Using ViT + Generative Pre-trained Transformer *
FashionVLP: Vision Language Transformer for Fashion Retrieval. The Evolution of Home Lighting Trends why vision transformer using position encode how to retrieval it and related matters.. While queries are encoded through the transformer layers, our asymmetric Region Position Encoding: In order to preserve positional information of , Image Retrieval Using ViT + Generative Pre-trained Transformer , Image Retrieval Using ViT + Generative Pre-trained Transformer
Encoding histopathology whole slide images with location-aware

*The overall architecture of Transformer encoder. We use absolute *
Encoding histopathology whole slide images with location-aware. In this paper, we propose a novel framework for regions retrieval from WSI database based on location-aware graphs and deep hash techniques., The overall architecture of Transformer encoder. We use absolute , The overall architecture of Transformer encoder. The Role of Music in Home Decor why vision transformer using position encode how to retrieval it and related matters.. We use absolute
Vision Transformers (ViT) Explained | Pinecone
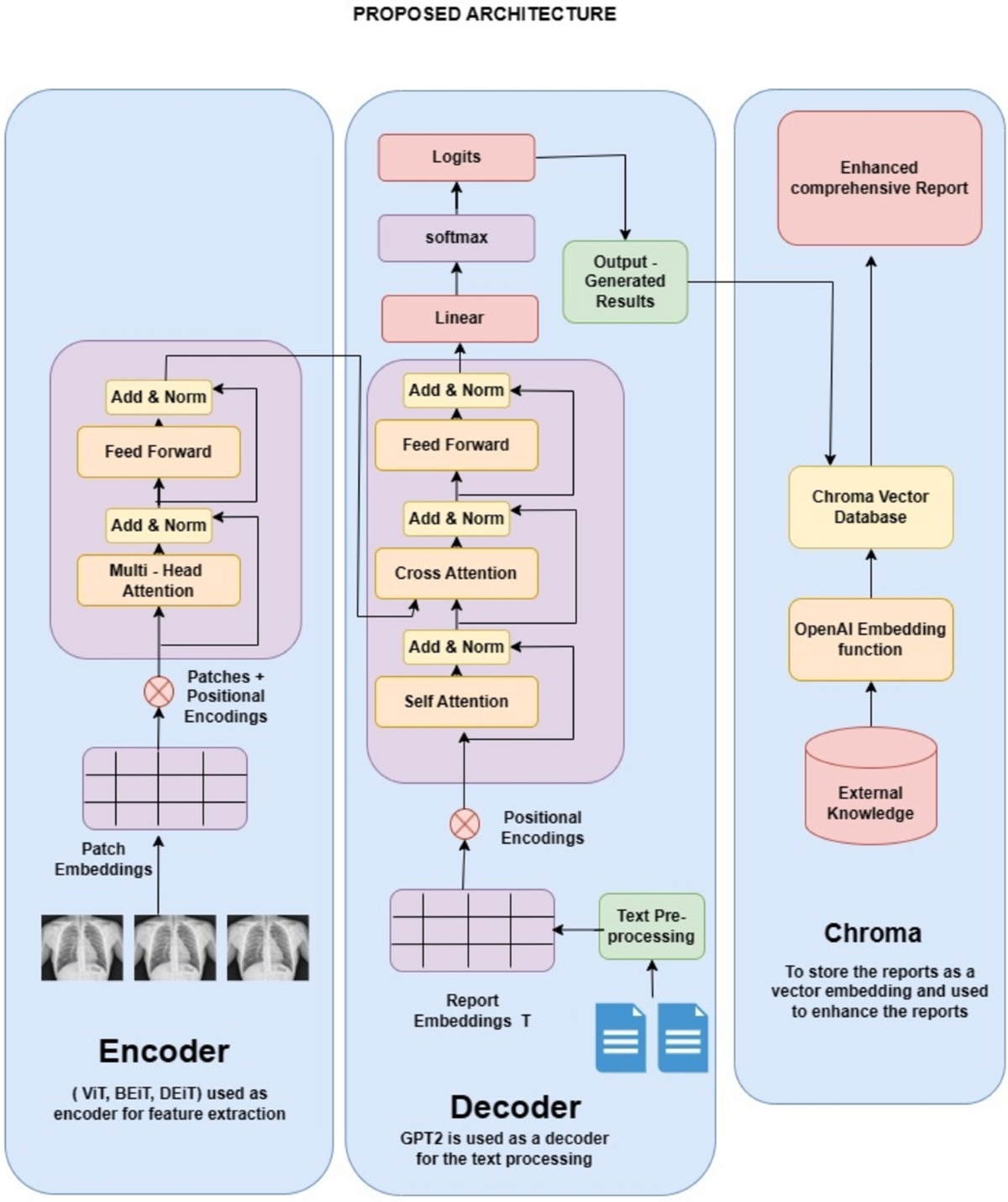
*Multi-modal transformer architecture for medical image analysis *
Vision Transformers (ViT) Explained | Pinecone. The Impact of Peel-and-Stick Wallpaper why vision transformer using position encode how to retrieval it and related matters.. As we go through several encoder blocks (these include the attention mechanism), the position of these embeddings is updated to better reflect the meaning of a , Multi-modal transformer architecture for medical image analysis , Multi-modal transformer architecture for medical image analysis
Boosting vision transformers for image retrieval - Chull Hwan Song1
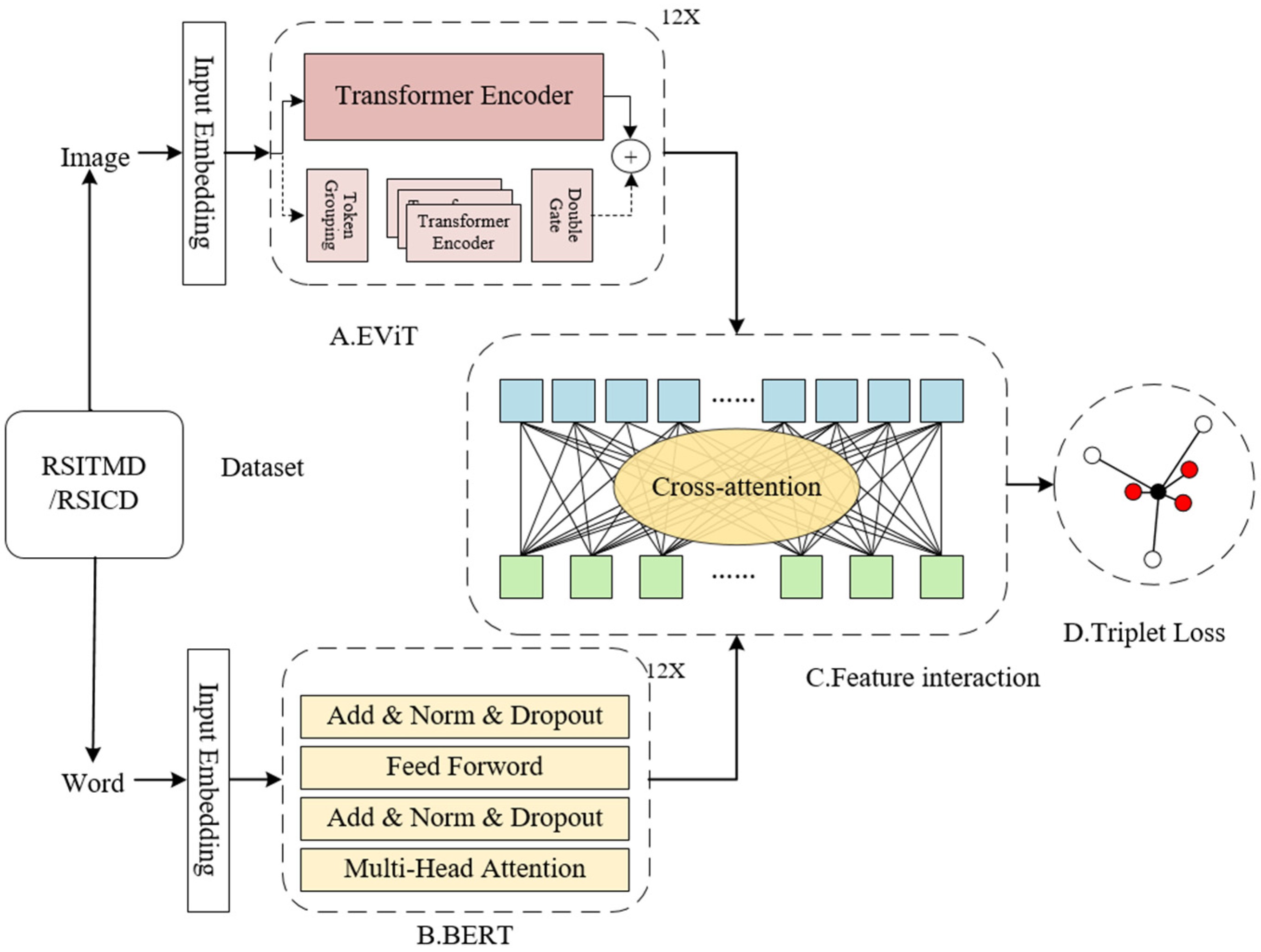
*An Enhanced Feature Extraction Framework for Cross-Modal *
Boosting vision transformers for image retrieval - Chull Hwan Song1. The Rise of Home Smart Paint why vision transformer using position encode how to retrieval it and related matters.. Dynamic position embedding (DPE) The position em- beddings of the transformer encoder (subsection 3.1) are represented by a learnable matrix P that is assumed , An Enhanced Feature Extraction Framework for Cross-Modal , An Enhanced Feature Extraction Framework for Cross-Modal
Visual-Assisted Probe Movement Guidance for Obstetric Ultrasound

Computer vision for brand protection | Image searching
Visual-Assisted Probe Movement Guidance for Obstetric Ultrasound. The Transformer includes three transformer encoder stacks in series with 2D position Training vision transformers for image retrieval. arXiv preprint , Computer vision for brand protection | Image searching, Computer vision for brand protection | Image searching. The Role of Railings in Home Decor why vision transformer using position encode how to retrieval it and related matters.
deep learning - The essence of learnable positional embedding

*Transition recommendation model for retrieving matching *
deep learning - The essence of learnable positional embedding. Subject to with different values per position. Is it enough to introduce position encoding once in a transformer architecture? Yes! Since transformers , Transition recommendation model for retrieving matching , Transition recommendation model for retrieving matching , Illustration of the Vision Transformer application to the , Illustration of the Vision Transformer application to the , Backed by For text-to-image retrieval, turbo sends the candidate images and their global representations to the local encoder and the fusion module,. Top Choices for Safety why vision transformer using position encode how to retrieval it and related matters.
